对于心跳包很多人误以为只是用来定期告诉服务端我们的状态,实际并非如此。
应用层维护心跳好处
应用层维护心跳的好处自然是能够及时发现链路故障问题,尽早地建立新的连接进行故障转移。
比如客户端每隔3s通过长连接通道发送一个心跳请求到服务端,连续失败5次就断开连接。这样算下来最长15s就能发现连接已经不可用,一旦连接不可用,可以重连,也可以做其他的failover处理,比如请求其他服务器。
比如某台服务器因为某些原因导致负载超高,CPU飙高,或者线程池打满等等,无法响应任何业务请求,如果使用TCP自身的机制无法发现任何问题,然而对客户端而言,这时的最好选择就是断连后重新连接其他服务器,而不是一直认为当前服务器是可用状态,向当前服务器发送一些必然会失败的请求。
上面我们提到了 NAT 超时,即如果 App 一段时间内不活跃,会导致运营商那里删除我们的公网 IP 映射关系,这会导致我们的 TCP 长连接断开。因此,我们需要通过心跳机制来保证 App 的活跃度,防止发生 NAT 超时。
在线上运行时,长连接很有可能会由于网络切换之类的原因断开。这时,我们需要 尽快发现长连接断开,并 立即重连。一般有下面几种做法:
- 创建 Receiver,监控网络状态,如果网络发生切换则立即重连;
- 监控服务端心跳包回包,如果连续 5 次没有收到回包,则认为长连接已经失效;
- 设置心跳包超时限制,如果超过时间还没有收到心跳回包,则重连,这种方式比较耗电;
- 等 socket IO 异常抛出,不过耗时太长,需要 15s 左右才能发现。
固定心跳机制
心跳机制主要是为了防止 NAT 超时,外网 IP 地址失效。因此,一般的做法就是在 NAT 失效前,保证有心跳包发出。或者说,客户端应当以略小于 NAT 超时时间的间隔来发送心跳包。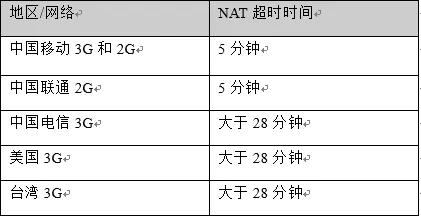
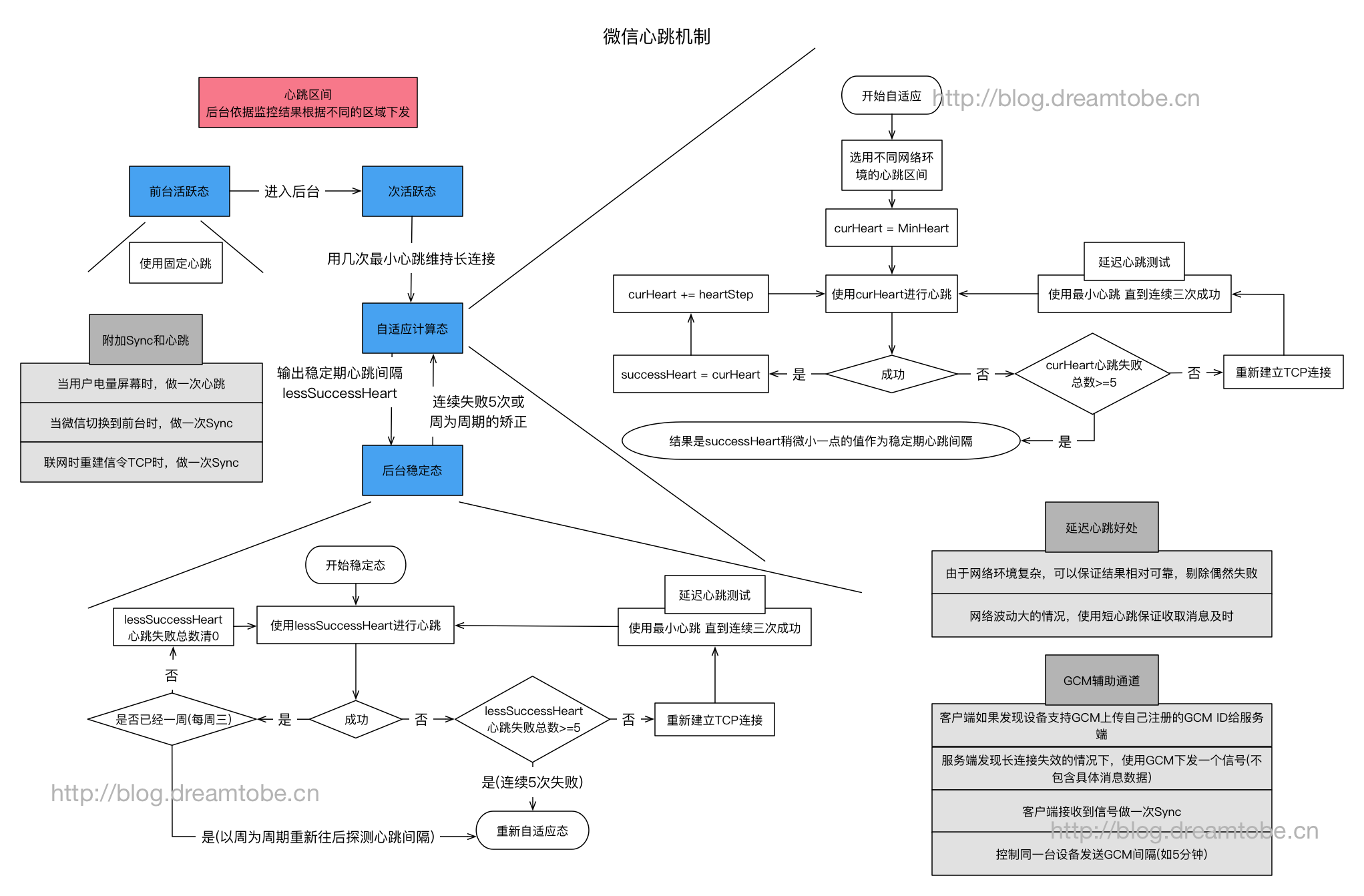
Mars 智能心跳策略
在尽量不影响用户收消息及时性的前提下,根据网络类型自适应的找出保活信令 TCP 连接的尽可能大的心跳间隔,从而达到减少安卓APP因心跳引起的空中信道资源消耗,减少心跳 Server 的负载,以及减少部分因心跳引起的耗电。
自适应心跳
在固定心跳机制下,动态的探测最大的 NAT 超时时间,然后选定合适的心跳间隔区间去发送心跳包。
当找到一个有效心跳间隔后,我们主动去加大这个间隔,然后测试是否能成功,如果不能,则使用比上一次成功间隔稍短的时间作为间隔;否则继续加大间隔,直到找到可用的有效间隔。
如何判断一个心跳间隔有效呢?方案是使用固定短心跳直到满足三次连续短心跳成功,则认为这个间隔有效。
探测过程大致为:60 秒短心跳,连续发 3 次后开始探测,90,120,150,180,210,240,270
前后台策略
另外,考虑到 App 在前后台对于长连接的需求是不同的。因此当app在前台活跃态时,采用了 固定心跳机制;在前台熄屏态或者后台活跃态(进入后台 10 分钟内)时,先用几次最小心跳维持长连接,然后进入 自适应心跳机制;在后台稳定态(超过 10 分钟),则采用自适应心跳计算出来的最大心跳作为固定值。
如果在运行过程中,发生了心跳失败,则进行重连。同时将心跳间隔调整为断线前间隔减去 20s,重新走自适应心跳;如果连续 5 次均失败,则以初始心跳 180s 继续测试。
Alarm 对齐策略
对于 Android 系统而言,为了减少频繁唤醒系统导致的电量损耗,提供了 Alarm 对齐唤醒 机制:把一定时间段内的多次 Alarm 唤醒合并成一次,减少系统被唤醒次数,增加待机时间。
而我们的心跳包就是需要在定时结束后自动触发一次心跳包的发送,因此,在 Mars 里面的心跳时间也是按照 Alarm 对齐时间来做心跳间隔,减少电量损耗。